
论文阅读 ACC:automatic ECN tuning for high-speed datacenter networks
paper: ACC: automatic ECN tuning for high-speed datacenter networks
Introduction & Background
核心问题
在高速数据中心网络(25Gbps ~ 100Gbps+)中,RDMA 被广泛使用以降低延迟。目前的拥塞控制机制(如 DCQCN)依赖于交换机上的 ECN(显式拥塞通知)标记。
- 现状: 现有的方案通常使用静态的 ECN 阈值($K_{min}, K_{max}, P_{max}$)。
- 挑战:
- 流量动态性: 流量模式随时间剧烈变化(例如:白天是延迟敏感的 OLTP,晚上是吞吐量敏感的 OLAP),静态设置无法同时满足低延迟和高吞吐的需求 。
- 手动调优困难: 这种微调通常需要数周时间,且网络中存在异构设备(不同厂商的网卡和交换机),使得统一配置变得不可能 。
- 目标: 实现“零配置(Zero-configuration)”,即通过机器学习自动在交换机运行时动态调整 ECN 阈值。
现有方法的局限性 (Observations)
论文通过实验指出了静态设置的三大缺陷:
- 不同流量模式需要不同的最优设置: 图 1 展示了在 Incast 场景下,不同并发度和负载下的最佳 ECN 阈值截然不同 。
- 静态设置在运行时表现不佳: 图 2 比较了三种静态设置(DCTCP, DCQCN, HPCC 的推荐值)。结果显示,激进的标记(低阈值)虽然降低了延迟,但损害了吞吐量;保守的标记(高阈值)则导致队列堆积,增加了长尾延迟 。
- 参数调优极其耗时: 需要在延迟和吞吐量之间做复杂的权衡 。
ACC Design
这是论文的核心部分,提出了一个基于多智能体强化学习(Multi-agent RL)的分布式架构。
为什么选择分布式而非集中式?
论文详细论证了为什么中心化的 RL 控制器(类似于 SDN 控制器)在高速网络中不可行:
- 状态空间爆炸: 假设有 1000 个交换机,每个交换机 48 个端口,每个端口有多个队列。状态空间将达到 $10^{96K \times NF}$(NF为特征数),动作空间同样巨大,导致模型无法收敛 。
- 延迟过高: 100G 网络的 RTT 仅为微秒级,中心化控制器的控制回路(采集+传输+推理+下发)耗时毫秒级,无法及时响应拥塞 。
- 带宽开销: 收集所有状态信息需要极高的带内遥测带宽(约 476Gbps)。
ACC 的选择: 在每个交换机上部署独立的 DRL 智能体(Agent),仅使用本地信息进行决策 。
强化学习模型构建 (MDP Formulation)
ACC 将 ECN 调优建模为马尔可夫决策过程(MDP)。
状态 (State, $S_t$)
智能体仅观测本地端口的统计信息。为了归一化并处理不同环境,选择了以下特征,并使用过去 $k=3$ 个时间步的历史数据来捕捉趋势 :
- 当前队列长度 ($qlen$)
- 链路输出速率 ($txRate$)
- ECN 标记的数据包速率 ($txRate(m)$)
- 当前的 ECN 设置 ($ECN(c)$)
动作 (Action, $a_t$)
动作是调整 ECN 的三个关键参数:$\{K_{max}, K_{min}, P_{max}\}$。为了减小动作空间,ACC 采用了离散化设计:
- $K_{max}$:采用粗粒度设置(如 1MB, 2MB 等),因为吞吐量对大阈值不敏感。
- $K_{min}$:关键数学设计。为了在拥塞时实现细粒度控制,使用了指数函数离散化 :其中 $\alpha = 20$ 。这意味着阈值在低负载区间更密集,便于精细控制。
- $P_{max}$:均匀离散化($\{1\%, 5\%, …, 100\%\}$)。

奖励函数 (Reward, $r_t$)
目标是平衡高吞吐和低延迟。
- $T(R) = txRate/BW$:链路利用率(越高越好)。
- $D(L)$:队列长度带来的惩罚。
- 关键设计: $D(L)$ 不是线性的,而是一个阶梯函数 (Step Function)(见图 4 )。
- 背景知识补充: 如果使用线性奖励 $1 - L/L_{max}$,由于 $L_{max}$ 通常很大(如 10MB),在低队列长度(如 50KB vs 100KB)时奖励差异微乎其微,导致 AI 无法区分优劣。阶梯函数在低队列区域变化剧烈,迫使 AI 极力保持低队列 。
算法:Deep Double Q-Network (DDQN)

ACC 使用 DDQN 来避免 Q-Learning 常见的过高估计(Overestimation)问题。
损失函数:
目标值计算(Double DQN 核心):
这里,动作的选择由当前网络 $\theta$ 决定,而动作的价值评估由目标网络 $\theta’$ 决定,从而解耦了选择和评估 。
异步训练 (Asynchronous Training): 每个交换机有本地经验回放池(Local Replay Memory),同时维护一个全局回放池。这允许智能体从整个网络的经验中学习,提高泛化能力。
Implementation
论文在商用交换机上实现了 ACC,架构如图 5 所示。
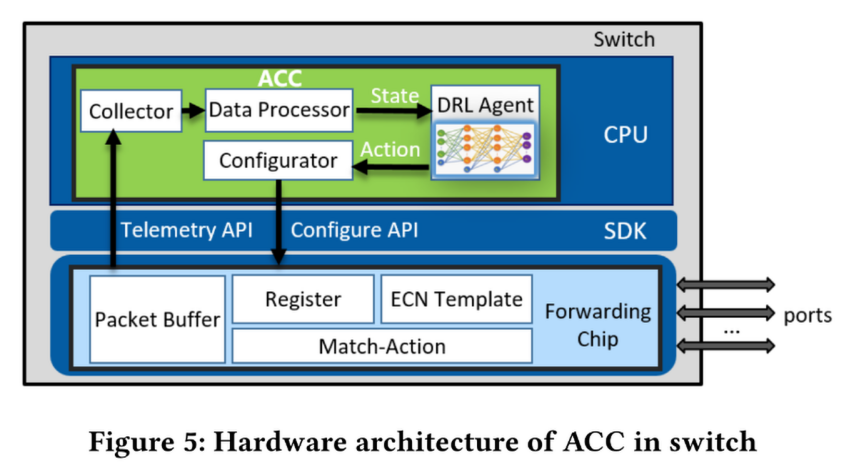
硬件架构: 利用交换机 SDK 读取寄存器(Telemetry API)并下发配置(Configure API)。代码量仅约 2400 行 C 代码 。
并行处理优化:
- 将队列分为 Busy 和 Idle。
- 如果队列长度小于 $K_{min}$ 且奖励连续三个时间步未变,标记为 Idle,停止推理以节省 CPU。
训练策略: 结合离线训练(Offline,使用各种 trace 预训练模型)和在线训练(Online,在实际部署中微调)。
Evaluation
微基准测试 (Micro-benchmark)
适应性: 图 6 显示,当流量模式改变时,静态 SECN 会出现队列积压或吞吐下降,而 ACC 能迅速调整阈值,稳定队列并保持高吞吐 。
公平性 (Fairness): 在 RDMA 与 TCP 混合部署时,TCP 通常会因为 RTT 较长而抢占 RDMA 的带宽。ACC 通过动态调整阈值,使得 RDMA 能够获得其分配的公平带宽份额(图 8)。
宏基准测试 (Macro-benchmark)
分布式存储: 在真实存储负载(如 FIO)下,ACC 相比静态设置,IOPS 提升了 20%-30% 。
分布式训练: 在 GPU 集群训练(ResNet-50)中,ACC 提高了训练速度,并显著降低了 PFC 暂停帧的数量(图 10)。
大规模仿真 (NS-3 Simulation)
使用 NS-3 模拟了 288 个节点的 Leaf-Spine 拓扑。
小流 (Mice Flows): FCT(流完成时间)降低了 17.3% (平均) 和 47.5% (99分位) 。
大流 (Elephant Flows): 保持了与高吞吐调优的静态设置相当甚至更好的性能 。
对比中心化方案: 仿真证明,中心化 ACC (C-ACC) 由于动作空间过大且只能对同一层级交换机做统一配置,性能远不如分布式 ACC (D-ACC)(图 14)。
Conclusion
ACC 是一个通过 DRL 实现网络内部自动优化的实用方案。
零配置: 无需人工干预 ECN 参数。
兼容性: 无需修改端侧(End-host)协议栈,兼容现有 NIC 和交换机芯片 。
性能: 在保证大流吞吐的同时,显著降低了小流的延迟。
REMARKS
可以借鉴的方面:
- Reward Function 的设计艺术: 没有使用简单的线性奖励,而是针对 Queue Length 设计了阶梯函数。这是解决 RL 在网络控制中“不敏感”问题的关键技巧。
- 状态归一化与历史窗口: 输入 State 时,不仅归一化了数据,还输入了过去 $k=3$ 个时间步的数据。这让 Agent 能够“感知”流量的导数(变化率),而不仅仅是瞬时值。这对处理突发流量(Micro-bursts)至关重要。
- 动作空间的离散化: 直接输出连续的阈值(Continuous Action)可能很难收敛。使用指数函数将 $K_{min}$ 离散化,这非常符合网络流量长尾分布的物理特性。
- 混合训练模式: 纯在线训练风险大,纯离线训练泛化差。提出的 Offline Pre-training + Online Fine-tuning 是工程落地的标准范式。
虽然这篇论文在 SIGCOMM 上的发表证明了其创新性,但在学术界和工业界(特别是涉及 RDMA 实际部署的社区)中,类似的“基于学习的网络优化(Learning-based Network Optimization)”方案通常面临着非常尖锐的审视。我的导师就认为将强化学习用于拥塞控制是一个幻想。
 PayPal/CreditCard
PayPal/CreditCard- 支付宝(Alipay)
- 微信(Wechat)










