
强化学习笔记
这不是一个完整的笔记,而是作为一个 attached link 附在 Zotero 上以做补充。
使用的教材:
https://github.com/MathFoundationRL/Book-Mathematical-Foundation-of-Reinforcement-Learning/tree/main
Bellman equation
关于式 2.7 的一些解释。
数学
这两个式子相等,是因为它们本质上是对同一组项进行求和,只是交换了求和的顺序。
在数学中,对于有限项的(或者绝对收敛的)双重求和,求和的顺序是可以任意交换的,这基于加法的交换律和结合律。
1. 第一个式子:
- 我们看内部的和 $\sum_{a \in A} \dots$ 。$v_\pi(s’)$ 位于这个和的外部。
- 由于 $v_\pi(s’)$ 不依赖于求和变量 $a$,我们可以将其移到内部求和的里面(把它当作一个系数):
- 现在,这就是一个标准的双重求和。它在对所有 $s’ \in S$ 和 $a \in A$ 的组合进行求和,求和的项是 $v_\pi(s’) p(s’|s, a)\pi(a|s)$。
2. 第二个式子:
- 我们看内部的和 $\sum_{s’ \in S} \dots$ 。$\pi(a|s)$ 位于这个和的外部。
- 由于 $\pi(a|s)$ 不依赖于求和变量 $s’$,我们也可以将其移到内部求和的里面:
- 根据乘法交换律,求和的项 $\pi(a|s) p(s’|s, a)v_\pi(s’)$ 与第一个式子中的项 $v_\pi(s’) p(s’|s, a)\pi(a|s)$ 是完全相同的。
- 所以,这同样是一个双重求和,它也在对所有 $s’ \in S$ 和 $a \in A$ 的组合进行求和。
结论:
两个式子实际上都在计算同一个总和:
这就像计算一个表格中所有数字的总和:
- 第一个式子是“先按行求和,再把每行的结果加起来”。
- 第二个式子是“先按列求和,再把每列的结果加起来”。
在强化学习中的理解
在强化学习的背景下(例如贝尔曼期望方程),这两个式子都用来计算从状态 $s$ 出发并遵循策略 $\pi$ 时,下一个状态的期望价值。
第二个式子(更直观):
- 内部 ( … ):计算在状态 $s$ 采取某个特定动作 $a$ 后,能转移到的下一个状态 $s’$ 的期望价值。
- 外部 $\sum_{a \in A} \pi(a|s) \dots$:因为你遵循策略 $\pi$,你会在 $s$ 处以 $\pi(a|s)$ 的概率选择动作 $a$。所以你用这个概率对所有可能的动作 $a$ 带来的期望价值进行加权平均。
第一个式子(数学等价):
- 内部 ( … ):计算从状态 $s$ 出发,最终转移到某个特定下一个状态 $s’$ 的总概率。这需要遍历所有可能导致 $s’$ 的动作 $a$,并将它们的路径概率($\pi(a|s) \times p(s’|s, a)$)相加。
- 外部 $\sum_{s’ \in S} v_\pi(s’) \dots$:用每个可能的下一个状态 $s’$ 的价值 $v_\pi(s’)$ 乘以你到达它的总概率,然后把所有 $s’$ 的结果加起来。
Examples for illustrating the Bellman equation
具体的代入方法:

Matrix-vector form of the BOE
和标量形式的联系:
Contraction mapping theorem

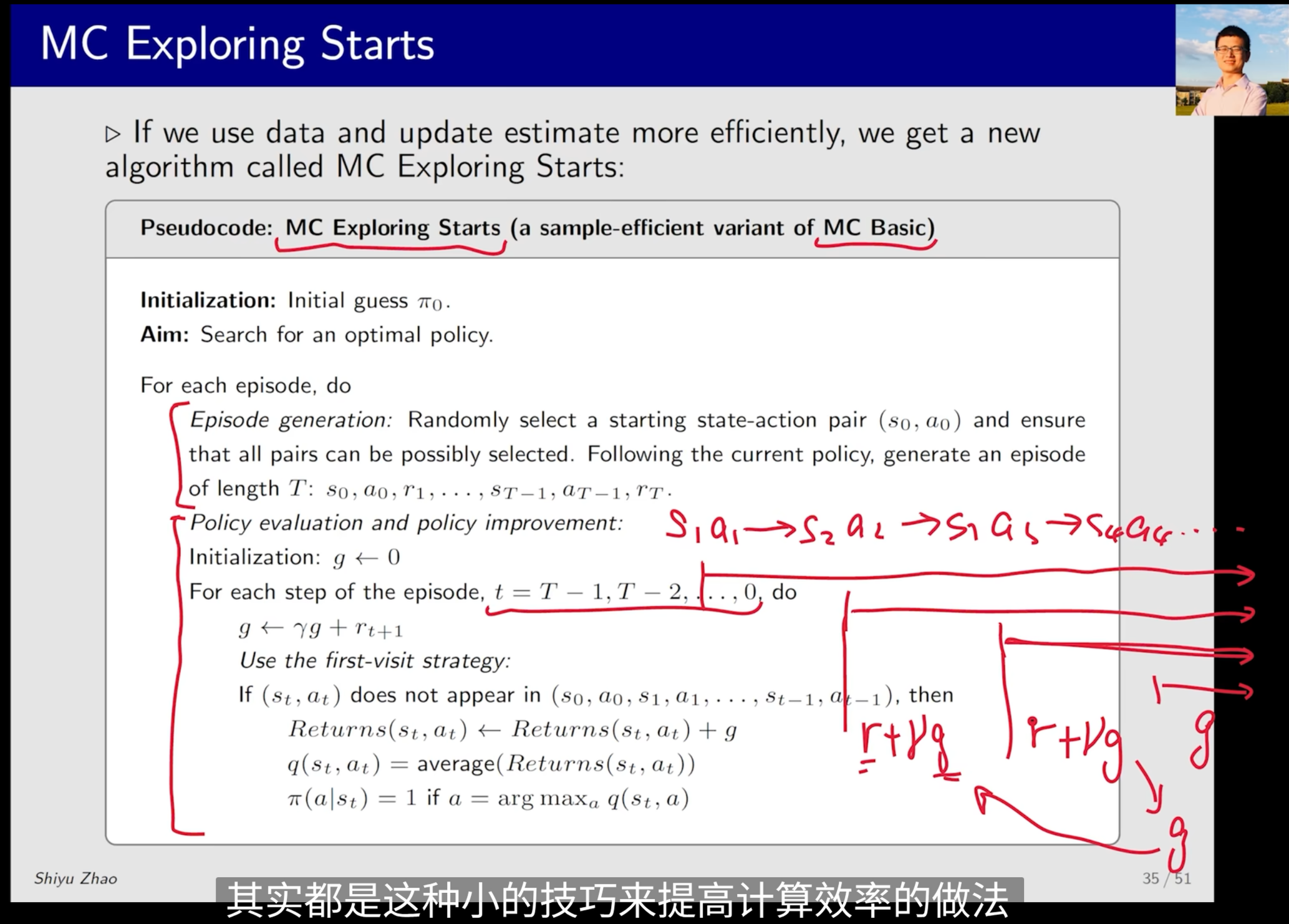
Updating policies more efficiently
Temporal-Difference Methods
一些引入的例子:



Off-policy vs on-policy



Deep Q-learning
原文中的神经网络(下)和简化版本(上)对比:

Policy Gradient Methods - Gradients of the metrics
具体的推导参考书中过程。

Actor-Critic Methods - The off-policy policy gradient theorem

这里不是 $\pi$,而是 $\beta$,它是一个固定的值。所以这里就没有什么探索,就是充分的利用。分母是不可变的。
DQN 代码实践
ref:
- https://hrl.boyuai.com/chapter/2/dqn%E7%AE%97%E6%B3%95
- https://github.com/boyu-ai/Hands-on-RL/blob/main/%E7%AC%AC7%E7%AB%A0-DQN%E7%AE%97%E6%B3%95.ipynb
从 TensorFlow (TF) 转到 PyTorch 时,最不适应的往往就是Tensor 形状的显式管理。TF(特别是 Keras)常常会在后台自动处理维度对齐,而 PyTorch 则要求你对每一层的数据流动的形状(Shape)有非常清晰的掌控,尤其是在处理 Batch 维度和计算 Loss 的时候。
网络定义阶段 (Qnet 类)
在 CartPole-v0 环境中,状态(State)是连续变量,动作(Action)是离散的。
- 输入层:
state_dim = 4(位置, 速度, 角度, 角速度)。 - 输出层:
action_dim = 2(向左, 向右)。
1 | class Qnet(torch.nn.Module): |
收集经验与采样 (ReplayBuffer 与 take_action)
单样本处理 (take_action)
在与环境交互时,我们一次只处理一个状态。但是 PyTorch 的层通常期望输入带有 Batch 维度。
1 | def take_action(self, state): |
批量采样 (ReplayBuffer.sample)
当 update 被调用时,我们从 Buffer 中采样出一个 Batch(代码中 batch_size=64)。此时数据的形状如下(均为 numpy array):
state:(64, 4)action:(64,)(注意这里通常是一维数组)reward:(64,)next_state:(64, 4)done:(64,)
核心训练逻辑 (DQN.update)
形状变化的重灾区。这是最容易通过不了编译或算错的地方。我们逐行拆解 update 函数中的 Tensor 变换。
数据预处理与维度调整
PyTorch 计算 Loss 时,通常要求维度严格匹配。
1 | # 原始 transition_dict['actions'] 是一个 list 或 numpy array,shape 为 (64,) |
为什么要变成 [64, 1]?
因为后续计算 Q 目标值时,公式是 $R + \gamma \max Q$,如果不扩展维度,[64] 和 [64, 1] 相加可能会触发 PyTorch 的广播机制(Broadcasting),导致生成 [64, 64] 的矩阵,这是非常经典的错误。
计算当前状态的 Q 值 (gather 操作)
我们需要计算网络对当前状态下,实际采取的那个动作的 Q 值。
1 | # 1. 计算所有动作的 Q 值 |
gather 的直观理解: 假设 Batch=2:
- Q_all =
[[1.5, 2.0], [3.0, 1.0]](形状 [2, 2]) - Actions =
[[1], [0]](形状 [2, 1],即第一个样本选了动作1,第二个选了动作0) - Result =
[[2.0], [3.0]](形状 [2, 1])
计算目标 Q 值 (max 操作)
我们需要计算下一个状态中,Q 值最大的那个动作对应的 Q 值(Target Q)。
1 | # next_states.shape: [64, 4] |
PyTorch 的 tensor.max(dim) 同时返回数值和索引。
计算 TD Error 并反向传播
1 | # 这里的加法和乘法都是 Element-wise 的 |
关于 CNN 部分 (ConvolutionalQnet)
代码最后附带了一个 CNN 网络,虽然在 CartPole 中没用到(CartPole 是向量输入),但如果是玩 Atari 游戏(图像输入),形状变化如下:
TF vs PyTorch 在图像上的区别:
- TensorFlow: 默认
(Batch, Height, Width, Channel)->NHWC - PyTorch: 默认
(Batch, Channel, Height, Width)->NCHW
代码解读:
1 | class ConvolutionalQnet(torch.nn.Module): |
PyTorch 训练模型
关于:
1 | dqn_loss = torch.mean(F.mse_loss(q_values, q_targets)) # 均方误差损失函数 |
这部分在 tensorflow 中直接 model.fit() 就可以了,在 PyTorch 中则有所不同。
简单回答
TensorFlow 的 model.fit() 是一个高度封装的“全自动”函数,而 PyTorch 的这段代码则是把 model.fit() 内部的“黑盒子”拆开来,让用户手动控制每一步。
在 TensorFlow (Keras) 中,当你调用 model.fit() 时,它在每一个 Batch 内部其实悄悄干了这三件事:
| 步骤 | PyTorch (手动挡) | TensorFlow Keras (自动挡 model.fit) | 动作含义 |
|---|---|---|---|
| 1 | dqn_loss = ... |
(内部自动计算) | 算错题:计算当前预测结果和真实结果的差距。 |
| 2 | optimizer.zero_grad() |
(内部自动执行) | 清空草稿纸:把上一次计算的梯度清零(PyTorch 特有机制)。 |
| 3 | dqn_loss.backward() |
(内部自动执行) | 找原因:反向传播,计算每个参数对误差的贡献(梯度)。 |
| 4 | optimizer.step() |
(内部自动执行) | 改错题:根据梯度和学习率,更新网络权重。 |
详细拆解
self.optimizer.zero_grad() 清空梯度
“为什么要手动清零?难道不应该每次都是新的吗?”
这是 PyTorch 的一个独特设计机制:梯度累加 (Gradient Accumulation)。
- 默认行为:PyTorch 的
backward()计算出的梯度,默认是累加到现有的梯度上的(grad += new_grad),而不是覆盖(grad = new_grad)。 - 如果不清零:你在第 1 个 Batch 算出的梯度,会和第 2 个 Batch 的梯度加在一起。用来更新权重时,方向就全乱了。
- 为什么这么设计? 假设你的显存很小,只能跑
Batch Size = 4,但你想达到Batch Size = 64的训练效果。你可以:- 不调用
zero_grad。 - 循环跑 16 次
backward()(累加梯度)。 - 调用 1 次
step()。这就是“变相扩大 Batch Size”的技巧。
- 不调用
但在常规训练(如 DQN)中,我们不需要累加,所以必须手动告诉 PyTorch:“这一轮训练开始了,把上一轮的梯度记录清空!”
dqn_loss.backward() 反向传播
“这行代码在做什么?”
dqn_loss是一个标量(Scalar,形状是[])。- 当你调用
.backward()时,PyTorch 的自动微分引擎(Autograd)会从dqn_loss这个节点出发,沿着计算图往回走。 - 它会找到所有参与计算且
requires_grad=True的权重参数(在q_net里),计算 loss 相对于这些参数的导数(梯度),并将结果存储在每个参数的.grad属性中。
self.optimizer.step() 参数更新
“这一步才是真正的学习。”
backward()只是算出了梯度(告诉参数该往哪里变),但参数本身还没有变。step()会读取每个参数里的.grad,并根据你设定的优化器算法(比如 Adam)和学习率(learning rate),执行下降操作 (注:Adam 的公式更复杂,但逻辑一致):
在 TensorFlow 中写“手动挡”?
其实 TensorFlow 也有完全一样的写法,叫 tf.GradientTape。如果去看 TF 的高阶代码或自定义训练循环,会发现逻辑和 PyTorch 差不多。
这种手动挡的方式在强化学习(RL)中特别重要,因为 RL 的训练循环通常不是标准的 Epoch/Batch 结构,而是由环境交互驱动的,PyTorch 这种灵活性在 RL 领域非常受欢迎。
滑动平均
只是一个代码里面的小细节,记录一下。
1 | def moving_average(a, window_size): |
这段代码实现了一个 保持输出长度不变(Same Length)的滑动平均(Moving Average) 算法。
在强化学习中,它通常被用来平滑(Smooth) 训练过程中的奖励(Reward)曲线,因为原始的 Reward 往往波动非常大,看不清趋势。
这段代码的写法非常“NumPy 风格”(向量化操作),比写 for 循环要快得多。为了呼应你对 向量/矩阵形状 的关注,我们把这段代码拆解成三部分来看:中间核心部分、开头部分 和 结尾部分。
假设:输入数组 a 的长度为 N,窗口大小 window_size 为 W(通常设为奇数)。
中间部分(核心逻辑)
1 | cumulative_sum = np.cumsum(np.insert(a, 0, 0)) |
这是计算滑动平均最高效的方法——积分图(Integral Image)技巧。
- 原理:如果不通过循环,怎么求数组中任意一段
[i, j]的和?- 先求前缀和
cumulative_sum(也就是累加值)。 - 区间
[i, j]的和 =cumulative_sum[j+1] - cumulative_sum[i]。
- 先求前缀和
- 形状变化:
np.insert(a, 0, 0):在a前面插入一个 0。形状从(N,)变为(N+1,)。cumulative_sum:形状也是(N+1,)。cumulative_sum[window_size:]:切掉了前 W 个,形状为(N+1-W,)。cumulative_sum[:-window_size]:切掉了后 W 个,形状为(N+1-W,)。- 相减:形状对齐,直接相减。这步操作一次性算出了所有“完整窗口”的和。
middle的最终形状:(N - W + 1, )。
问题:如果只保留 middle,输出长度会比输入长度少 W-1 个点。为了画图时横坐标对齐,我们需要把两头“补”回来。
开头部分(边界处理)
1 | r = np.arange(1, window_size-1, 2) |
当窗口在数组最左边滑动时,左边没有数据了。普通的做法是补 0(Padding),但这样会让平均值被拉低。这里的做法是:缩小窗口。
逻辑:
- 第 1 个点:用窗口大小 1 计算平均。
- 第 2 个点:用窗口大小 3 计算平均。
- … 直到窗口能扩张到 W 为止。
形状与细节:
r:分母数组[1, 3, 5, ..., W-2]。a[:window_size-1]:取前 W-1 个元素。np.cumsum(...):前缀和。[::2]:关键切片。每隔一个取一个数(对应取索引 0, 2, 4…)。这正好对应了累加 1 个数、累加 3 个数、累加 5 个数的和。begin的最终形状:( (W-1)/2, )(假设 W 是奇数)。
结尾部分(边界处理)
1 | end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1] |
和开头部分的逻辑完全对称:
- 先用
[::-1]把数组倒序。 - 用同样的逻辑计算变长平均。
- 最后再用
[::-1]把结果倒回来。 end的最终形状:( (W-1)/2, )。
总结:形状拼接
最后一步 np.concatenate 将这三部分拼起来:
结论:
这段代码的作用是 对输入序列 a 进行平滑处理,且保证输出序列的长度(Shape)与输入完全一致 (N,)。
为什么你要懂这个?
在 Deep Learning 代码中,你经常会在 train 结束后看到类似这样的调用:
1 | # return_list 是每个 episode 的奖励,波动剧烈 |
如果你不处理边界(只用 middle),episodes_list 和 mv_return 的长度就会不匹配(差了8个点),Matplotlib 就会报错 x and y must have same first dimension。这段代码就是为了解决这个形状对齐问题的。
Double DQN
ref:
- https://hrl.boyuai.com/chapter/2/dqn%E6%94%B9%E8%BF%9B%E7%AE%97%E6%B3%95/
- https://github.com/boyu-ai/Hands-on-RL/blob/main/%E7%AC%AC8%E7%AB%A0-DQN%E6%94%B9%E8%BF%9B%E7%AE%97%E6%B3%95.ipynb
原理
链接中的解释有点晦涩,我提出自己的理解,但不能保证其正确性。
在 DQN 中,在计算
时,我们的做法是:

然后,做两件事:选择 value 最大的 action, 将它的值返回。
这会导致误差的积累。例如,Target Net 对 a2 作出了过高估计,由式 (8.38),
会被过高估计,因为我们旨在降低目标函数的值(should equal zero in the expectation sense),从而导致 $\hat{q}(S, A, w)$ 被过高估计。
这样的误差将会逐步累积。对于动作空间较大的任务,DQN 中的过高估计问题会非常严重,造成 DQN 无法有效工作的后果。
Double DQN 的解决方法是:
使用训练网络选取 action, 目标网络计算 value. 即,我们需要减少
与 $\color{green}{\hat{q}(S, A, w)}$ 的差距。
这些误差是由神经网络本身带来的,Double DQN 并不能避免误差,但是这两个网络的误差“方向”可能不一样。
但是这在理论上带来了新的问题,式 (8.38) 是 $J$ 对 $w$ 求导,在原来的
中,不包含 $w$. Double DQN 却引入了 $w$, 在求导的时候会带来困难。
关于“梯度求导”的理论担忧,在深度强化学习的实际操作(Semi-gradient 方法)中,这个问题的处理方式比较“简单粗暴”。
- 数学与工程实现的解释:
- Semi-gradient (半梯度) 方法:在 Q-learning 及其变体(包括 DQN)中,我们使用的是半梯度方法。这意味着,在计算梯度时,我们强制将目标值 $Y$ 视为常数(Constant)。
- 即使 $Y$ 的计算过程用到了 $w$(用来选动作),我们在反向传播时,会切断这部分的梯度流。
- 这正如书中所说:“For the sake of simplicity, it is assumed that the value of $w$ in $y$ is fixed”。这个假设在 Double DQN 中依然适用。
- Argmax 的不可导性:从数学角度看,$\text{argmax}$ 操作本身是离散的、分段常数的(Step function)。在绝大多数点上,$\text{argmax}$ 的导数为 0;在跳变点上,导数未定义。因此,即使想对它求导,梯度也传不回去。
- 理解为“噪声”?:“是否可以简单理解为引入了一种噪声”?
- 这不完全准确。它不是随机噪声,而是一种去偏(De-biasing)机制。
- 与其说是噪声,不如说是 “交叉验证”。我们在用网络 A 告诉我们“谁是第一名”,然后问网络 B “第一名考了多少分”。这打破了“自卖自夸”(用网络 A 选第一名,又用网络 A 打分)带来的正向偏差循环。
- Semi-gradient (半梯度) 方法:在 Q-learning 及其变体(包括 DQN)中,我们使用的是半梯度方法。这意味着,在计算梯度时,我们强制将目标值 $Y$ 视为常数(Constant)。
部分代码细节
1 | def dis_to_con(discrete_action, env, action_dim): # 离散动作转回连续的函数 |
这段代码用于解决 DQN 只能处理离散动作 与 倒立摆环境(Pendulum-v0)需要连续动作 之间的矛盾。
它本质上是一个 线性插值(Linear Interpolation) 函数,将神经网络输出的离散索引(如 0, 1, 2…)映射回环境实际需要的连续物理数值(如力矩 -2.0, -1.6…)。
环境限制:Pendulum-v0 环境的动作是一个连续的力矩值,范围是 $[-2.0, 2.0]$ 。
算法限制:DQN 算法只能输出离散的动作编号(即选择第几个动作)。
解决方案:将连续的动作空间“切分”成若干份(文中设为 action_dim = 11),用离散的编号 0 到 10 来代表这些切分点 。
1 | def dis_to_con(discrete_action, env, action_dim): |
这个返回值的计算公式可以理解为:
- 总跨度 (
action_upbound - action_lowbound):即 $2.0 - (-2.0) = 4.0$ 。这是动作值的变动总范围。 - 比例 (
discrete_action / (action_dim - 1)):discrete_action是当前神经网络选出的动作编号(例如 0, 5, 10)。action_dim - 1是最大的动作编号(因为编号从0开始,11个动作的最大编号是 10)。- 这个部分计算当前动作在所有动作中排在什么位置(百分比)。例如,编号 0 对应 0%,编号 5 对应 50%,编号 10 对应 100%。
Actor-Critic
1 | class ActorCritic: |
这段代码实现了Actor-Critic算法中的策略和价值更新部分。
与算法的对应关系
Actor-Critic算法结合了策略梯度方法(Actor)和价值函数近似(Critic)的优点:
- Actor(策略网络): Actor负责生成动作,它的目标是通过策略梯度方法,最大化累计的预期回报。
- Critic(价值网络): Critic估计每个状态的价值(即状态的预期累计回报)。Critic用于评估Actor的动作质量以及改进Actor。

代码中的实现:
1 | # 时序差分目标 (Temporal Difference Target) |
这部分计算了时序差分目标(TD Target),即当前奖励rewards加上未来状态的折扣价值(通过self.critic(next_states)估算)。
1 | # 时序差分误差 (Temporal Difference Error, TD Error) |
这部分计算了时序差分误差(Temporal Difference Error, (\delta)),即TD目标与当前状态价值估计的差值。
1 | # 策略损失 (Policy Loss) |
这部分计算了Actor(策略网络)的损失:
self.actor(states)输出每个 action 的概率分布。gather(1, actions)提取选择的动作的概率。log_probs生成动作概率的对数值。- $-\log\pi(a|s) \cdot \delta$ 是策略梯度的目标。
注意:通过detach(),TD误差从计算图中分离出,避免Critic的梯度影响Actor。
Actor的目标是最大化累计奖励,等价于最小化负的策略梯度目标(上式中的负号带来最大化效果)。
1 | # 价值函数损失 (Value Function Loss) |
这部分计算了 Critic(价值网络)的损失:TD 目标和 Critic 输出的均方误差(MSE)。Critic 的目标是对真实的 TD 目标进行逼近。
求导过程
求导的过程体现在以下几行代码:1
2
3
4
5
6self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward() # 计算策略网络的梯度
critic_loss.backward() # 计算价值网络的梯度
self.actor_optimizer.step() # 更新策略网络的参数
self.critic_optimizer.step() # 更新价值网络的参数
具体说明:
actor_loss.backward(): 这一行触发了PyTorch的自动微分机制,计算Actor网络(策略网络)中所有参数的梯度。这些梯度是相对于actor_loss计算的,由链式法则自动完成。critic_loss.backward(): 类似地,这一行计算了 Critic 网络(价值网络)中所有参数的梯度。- 后续通过
step()来使用优化器(Adam算法)更新网络参数。
detach() 的作用
detach()的作用是从当前的计算图中分离出一个张量,截断其反向传播的梯度流。这在代码中有两处应用:
1 | actor_loss = torch.mean(-log_probs * td_delta.detach()) |
- 防止Critic的梯度影响Actor:
- 这里的
td_delta由td_target - self.critic(states)计算而来,其值本质上依赖 Critic。如果直接用它计算actor_loss,在求Actor梯度时,Critic的梯度也可能会被更新。 detach()使得td_delta看起来像常量,确保 Actor 和 Critic 独立优化。
- 这里的
1 | critic_loss = torch.mean( |
- 使TD目标成为常数:
td_target依赖于 Critic 的预测(self.critic(next_states))。若不使用detach(),则在计算 Critic 损失时会导致梯度传播到td_target的生成过程,这样优化无意义。
env.step()
代码链接: https://github.com/boyu-ai/Hands-on-RL/blob/main/rl_utils.py
1 | def train_on_policy_agent(env, agent, num_episodes): |
这个 env.step() 是如何返回 done 的?
在强化学习中,env.step(action)的行为取决于环境的具体实现。在这段代码中,env是由gym.make(env_name)创建的,这表明使用的是 OpenAI Gym 环境,而env.step(action)是 Gym 接口规定的一个标准方法。
env.step(action) 如何工作
env.step(action)的调用会执行以下操作:
- 环境的状态更新:
- 根据
action的输入,环境会通过其内部的动态模型生成下一步的状态next_state。
- 根据
- 奖励计算:
- 根据
action与状态转移,环境输出即时奖励reward,这个奖励通常与任务的目标相关,用于指导强化学习算法优化行为。
- 根据
- 检查是否结束:
- 返回标志
done,指示回合是否结束。done=True表示当前episode(轨迹)结束,智能体需要重新开始下一回合。
- 返回标志
- 额外信息:
- 返回
specific info(通常是调试和分析用的辅助信息)。
- 返回
Gym的env.step(action)返回值如下:
1 | next_state, reward, done, info = env.step(action) # 新版 Gym 有差异,稍加注意 |
next_state:此动作后得到的环境状态。reward:即时奖励(通常为一个浮点数)。done:布尔值,是否到达终止状态(如果为True,当前轨迹结束)。info:额外信息字典(不用于学习,一般用来调试或显示)。
done 如何生成
done的生成规则由环境的设计逻辑决定,不同环境可能有不同的终止条件。对于OpenAI Gym中的典型环境,例如CartPole-v0,它的done会根据固定的规则返回:
- 达到了最大步骤限制。 在OpenAI Gym里面,绝大多数任务都有一个预定义的最大步数限制(泛化表述)。如果智能体未达到终止状态,但走满了最大步数,当前回合会强制终止。
- 达到失败条件。 大多数环境会根据任务定义失败条件。例如在
CartPole-v0中,杆子角度偏离阈值或小车位置超出轨道范围,当前轨迹就会结束。
batch 视角
在这个代码中,PyTorch 是支持按 batch 进行训练的,而且这个训练过程是按 batch 设计的。我们从代码可以看出,数据操作部分就是按照 batch 来设计和处理的。
关键代码与batch处理
1 | states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device) |
transition_dict是一个字典,用于存储多个(不仅是单一)状态、动作、奖励等的样本。transition_dict['states']:形状为[batch_size, state_dim],存储当前 batch 中所有状态。transition_dict['actions']:形状为[batch_size],存储当前 batch 中所有动作。transition_dict['rewards']:形状为[batch_size],存储当前 batch 中所有即时奖励。transition_dict['next_states']:形状为[batch_size, state_dim],存储当前 batch 中所有的下一个状态。transition_dict['dones']:形状为[batch_size],存储当前 batch 中每个样本是否完成(终止)。
注意一点小区别,这里是整条 trajectory 作为一个 batch,也就是说:transition_dict里面装的是一整条 episode 的数据,而不是随机采样的小批量 。
| 类型 | 本节代码 | DQN等 |
|---|---|---|
| 数据来源 | 单条完整轨迹 | replay buffer 随机采样 |
| 是否打乱 | 否 | 是 |
| 是否跨 episode | 否 | 是 |
因此,该实现是“基于整条 episode 的 on-policy 批量更新”,而不是随机 mini-batch 训练。
网络处理按batch输入
在更新过程中,actor 和 critic 网络接收的是以 batch 形式进行的输入:
1 | probs = self.actor(states) |
- Actor网络:
- 输入:
self.actor(states)中,states的形状是[batch_size, state_dim],即当前 batch(一次更新)中所有样本的状态。 - 输出:形状为
[batch_size, action_dim],包含各个样本对应动作的概率分布。
- 输入:
- Critic网络:
- 输入:
self.critic(states)和self.critic(next_states)中,states和next_states的形状是[batch_size, state_dim]。 - 输出:形状为
[batch_size, 1],批量计算每个输入状态的估值。
- 输入:
因此,Actor 和 Critic 网络的前向传播都是在整个 batch 上进行的,而不是样本逐一处理。
梯度计算与参数更新按batch进行
在这里,损失函数是针对整个 batch 计算的:
1 | actor_loss = torch.mean(-log_probs * td_delta.detach()) |
- Actor损失:
log_probs:形状为[batch_size, 1]。td_delta: 形状也为[batch_size, 1]。torch.mean()对batch中的所有样本的损失取平均,从而得到平均损失。
- Critic损失:
F.mse_loss按batch计算样本点的均方误差后,再对所有样本取均值。
然后,通过以下操作计算梯度并更新参数:
1 | self.actor_optimizer.zero_grad() |
backward()会计算整个 batch 上累积的梯度。- 优化器 (
self.actor_optimizer和self.critic_optimizer) 在更新时使用的是整个 batch 的梯度。
是否可以扩展到单样本(非batch)训练?
虽然这个代码是按 batch 处理数据的,但如果仅给transition_dict传入一个样本(即 batch_size=1),PyTorch 也能正常运行。这种情况下,输入张量的形状类似于以下:
states:形状[1, state_dim]。actions:形状[1]。rewards:形状[1, 1]。next_states:形状[1, state_dim]。dones:形状[1, 1]。
代码逻辑不会崩溃,但效率较低且不利于梯度估计的稳定性。
 PayPal/CreditCard
PayPal/CreditCard- 支付宝(Alipay)
- 微信(Wechat)










